Artificial intelligence systems are becoming increasingly capable of:
- reasoning,
- planning,
- coding,
- tool usage,
- and autonomous decision-making.
As these systems grow more complex, one challenge becomes critically important:
How do we measure whether AI systems are actually reliable, accurate, and trustworthy?
This is the role of benchmarks and evaluation systems.
Modern AI evaluation goes far beyond simple accuracy scores. Today’s reasoning systems must be assessed across:
- logical consistency,
- reasoning quality,
- planning ability,
- coding performance,
- hallucination rates,
- robustness,
- safety,
- and real-world task completion.
This hub explores the benchmarks, metrics, methodologies, and evaluation architectures shaping modern reasoning AI systems.
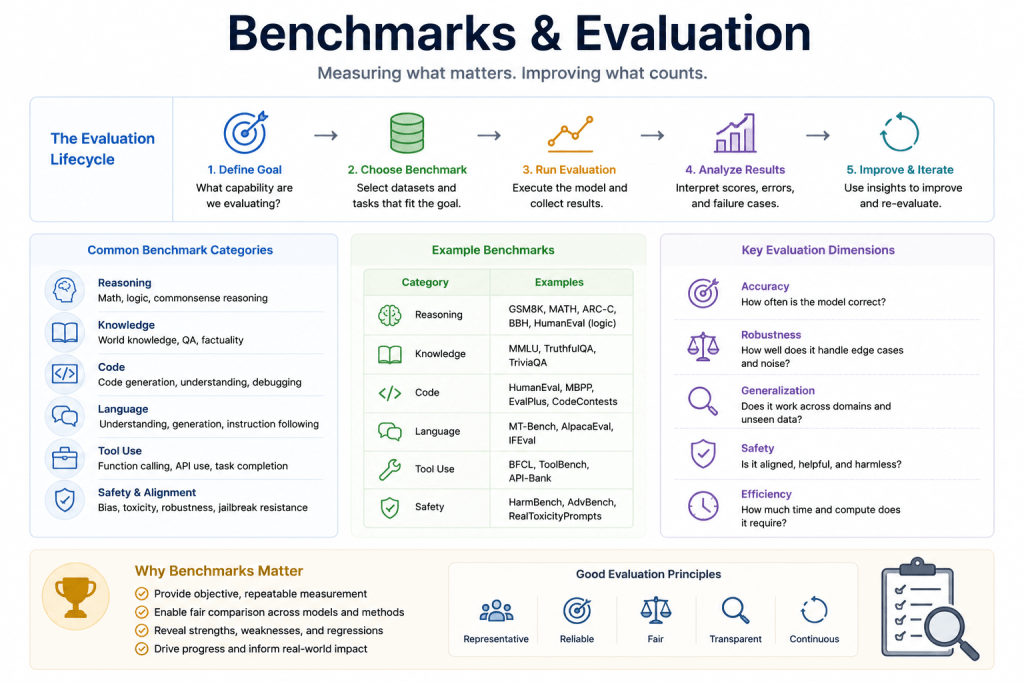
What Are AI Benchmarks?
An AI benchmark is a structured testing framework used to measure the capabilities and limitations of an AI system.
Benchmarks help researchers and engineers evaluate:
- reasoning ability,
- factual accuracy,
- coding skill,
- mathematical performance,
- planning capability,
- tool use,
- and autonomous execution.
Benchmarks are essential because AI systems can often:
- sound convincing while being incorrect,
- memorize instead of reason,
- fail unpredictably,
- or produce inconsistent outputs.
Evaluation frameworks attempt to measure these weaknesses systematically.
Why Evaluation Matters
As AI systems become more autonomous, evaluation becomes one of the most important engineering disciplines in artificial intelligence.
Modern reasoning systems are increasingly used in:
- software engineering,
- healthcare,
- cybersecurity,
- finance,
- scientific research,
- and enterprise automation.
Failures in these systems can lead to:
- hallucinations,
- incorrect decisions,
- unsafe actions,
- reasoning breakdowns,
- or unreliable autonomous behavior.
This means modern AI development increasingly depends on:
- rigorous testing,
- reliability measurement,
- robustness analysis,
- and evaluation pipelines.
Core Areas of AI Evaluation
Modern AI evaluation spans multiple dimensions.
Reasoning Benchmarks
Reasoning benchmarks measure whether AI systems can:
- solve multi-step problems,
- apply logic,
- maintain consistency,
- and reason beyond memorization.
These benchmarks are central to modern reasoning AI research.
Popular reasoning benchmarks include:
- GSM8K,
- MATH,
- GPQA,
- BigBench Hard,
- and ARC-AGI.
Reasoning evaluation focuses on:
- intermediate reasoning quality,
- logical consistency,
- planning ability,
- and generalization.
Related articles:
- What Is GSM8K?
- Understanding ARC-AGI
- GPQA Explained
- Reasoning vs Memorization
- Why Multi-Step Reasoning Is Difficult
Coding Benchmarks
Modern AI systems are increasingly evaluated on software engineering tasks.
Coding benchmarks measure:
- code generation,
- debugging,
- reasoning about software,
- and repository-level problem solving.
Important benchmarks include:
- HumanEval,
- MBPP,
- SWE-bench,
- and agentic coding evaluations.
These tests are becoming increasingly important as autonomous coding agents evolve.
Related articles:
- What Is SWE-bench?
- HumanEval Explained
- Evaluating AI Coding Agents
- Repository-Level Reasoning Systems
Hallucination Evaluation
One of the biggest challenges in AI systems is hallucination:
- generating false,
- misleading,
- or fabricated information.
Hallucination evaluation attempts to measure:
- factual consistency,
- grounding,
- citation reliability,
- and confidence calibration.
This is especially important in:
- enterprise AI,
- research systems,
- healthcare,
- and autonomous agents.
Related articles:
- Hallucination Detection Explained
- Factual Consistency in AI
- Grounded Reasoning Systems
- Why AI Hallucinates
Agent Evaluation
Traditional benchmarks often fail to measure autonomous agent behavior effectively.
Modern agent evaluation focuses on:
- task completion,
- planning quality,
- tool usage,
- workflow execution,
- and long-horizon reasoning.
Agent systems must often be evaluated dynamically within interactive environments.
This creates new challenges in:
- reproducibility,
- state tracking,
- reliability,
- and behavioral consistency.
Related articles:
- Evaluating AI Agents
- Benchmarking Autonomous Systems
- Long-Horizon Task Evaluation
- Agent Reliability Metrics
Robustness Testing
AI systems often fail when exposed to:
- adversarial inputs,
- unexpected environments,
- ambiguous instructions,
- or distribution shifts.
Robustness testing evaluates whether systems remain reliable under changing conditions.
This includes:
- adversarial testing,
- stress testing,
- safety evaluation,
- and uncertainty analysis.
Related articles:
- Adversarial Evaluation
- Distribution Shift Explained
- Stress Testing AI Systems
- Robustness in Reasoning Models
Reliability and Consistency Metrics
Modern AI systems must be evaluated not only on correctness, but also on consistency.
Important evaluation dimensions include:
- repeatability,
- confidence calibration,
- reasoning stability,
- and deterministic behavior.
Two systems may both reach the correct answer:
- but one may reason reliably,
- while another succeeds inconsistently.
Reliability metrics are increasingly important for:
- enterprise deployment,
- autonomous agents,
- and production AI systems.
Related articles:
- AI Reliability Metrics
- Confidence Calibration
- Consistency Evaluation
- Deterministic vs Stochastic Reasoning
Process Supervision
Traditional evaluation often focuses only on:
the final answer.
Process supervision evaluates:
how the reasoning process itself unfolds.
This includes assessing:
- intermediate reasoning steps,
- planning quality,
- logical structure,
- and reasoning traces.
Process supervision is becoming increasingly important in reasoning model research.
Related articles:
- Process Supervision Explained
- Verifier Models
- Reasoning Trace Evaluation
- Intermediate Step Validation
Human Evaluation
Not all AI performance can be measured automatically.
Human evaluation is still widely used for:
- creativity,
- helpfulness,
- instruction following,
- and nuanced reasoning quality.
Human evaluators may assess:
- coherence,
- usefulness,
- factual reliability,
- and behavioral alignment.
Human feedback also plays a major role in:
- RLHF,
- preference modeling,
- and alignment training.
Related articles:
- Human Evaluation in AI
- RLHF Explained
- Preference Modeling Systems
- Alignment Evaluation
Evaluation Frameworks and Infrastructure
Modern AI evaluation increasingly depends on specialized infrastructure.
Evaluation systems may include:
- automated testing pipelines,
- benchmark harnesses,
- simulation environments,
- verifier systems,
- and orchestration frameworks.
As reasoning systems become more autonomous, evaluation infrastructure becomes more complex.
Related articles:
- Benchmark Harnesses Explained
- AI Evaluation Pipelines
- Automated Reasoning Evaluation
- Simulation Environments for AI
Emerging Trends in AI Evaluation
The field of AI evaluation is evolving rapidly.
Major emerging trends include:
- dynamic benchmarks,
- adversarial testing,
- agentic evaluation,
- process-based scoring,
- multimodal evaluation,
- real-world task assessment,
- and continuous evaluation pipelines.
The industry is increasingly recognizing that:
benchmark scores alone are not sufficient to measure intelligence or reliability.
Future evaluation systems will likely focus more heavily on:
- adaptability,
- planning,
- autonomy,
- and long-term reasoning behavior.
Why Traditional Benchmarks Are Becoming Insufficient
Many older benchmarks are reaching saturation.
Modern frontier models can often:
- memorize benchmark patterns,
- exploit dataset weaknesses,
- or optimize specifically for public leaderboards.
This creates challenges such as:
- benchmark contamination,
- overfitting to evaluation datasets,
- and inflated capability estimates.
As a result, the industry is increasingly moving toward:
- harder reasoning tasks,
- dynamic evaluations,
- hidden test sets,
- and interactive environments.
Benchmarks and Autonomous AI Systems
Evaluation becomes significantly harder once AI systems gain autonomy.
Autonomous agents may:
- make decisions over long time horizons,
- interact with tools,
- modify environments,
- and adapt dynamically.
This means evaluation must increasingly measure:
- planning quality,
- reliability,
- tool execution,
- memory usage,
- and behavioral consistency.
Agent evaluation is becoming one of the most important frontiers in AI engineering.
Practical Applications of AI Evaluation
Evaluation systems are now central to:
- enterprise AI deployment,
- autonomous coding systems,
- AI safety research,
- model benchmarking,
- scientific AI,
- and production AI operations.
Organizations increasingly require:
- monitoring systems,
- evaluation dashboards,
- automated testing pipelines,
- and reliability frameworks.
As reasoning systems become integrated into real-world workflows, evaluation infrastructure becomes mission-critical.
Python and Practical Evaluation Workflows
ReasoningSystems.org focuses not only on evaluation theory, but also on practical implementation.
Throughout this hub, you will find:
- Python-based evaluation workflows,
- benchmark pipelines,
- hallucination detection examples,
- scoring systems,
- agent testing frameworks,
- and GitHub-linked implementations.
The goal is to understand not only:
what AI evaluation is,
but also:
how modern reasoning systems can be tested, validated, and monitored in practice.
Explore the Benchmarks & Evaluation Hub
This hub serves as a central entry point for understanding how modern AI systems are:
- measured,
- tested,
- validated,
- and monitored.
Whether you are:
- researching reasoning models,
- evaluating AI agents,
- studying benchmark design,
- or building reliable AI systems,
evaluation is rapidly becoming one of the foundational disciplines of modern artificial intelligence engineering.
Recommended Starting Articles
- What Is GSM8K?
- Understanding ARC-AGI
- What Is SWE-bench?
- Hallucination Detection Explained
- Evaluating AI Agents
- Process Supervision Explained
- Reliability Metrics for AI Systems
- Distribution Shift Explained
- Human Evaluation in AI
- Benchmark Contamination Explained
