Retrieval-Augmented Generation (RAG) has become one of the foundational architectures behind modern AI systems.
Instead of relying only on:
- model memory,
- static training data,
- or internal parameters,
RAG systems allow AI models to:
- retrieve external information,
- access documents dynamically,
- and ground reasoning in real data.
This dramatically improves:
- factual accuracy,
- context awareness,
- enterprise usability,
- and reasoning reliability.
RAG pipelines are now widely used in:
- enterprise AI,
- AI agents,
- coding assistants,
- customer support systems,
- internal knowledge platforms,
- and autonomous reasoning architectures.
This article explains:
- what a RAG pipeline is,
- how it works,
- and how to build one step-by-step using Python.
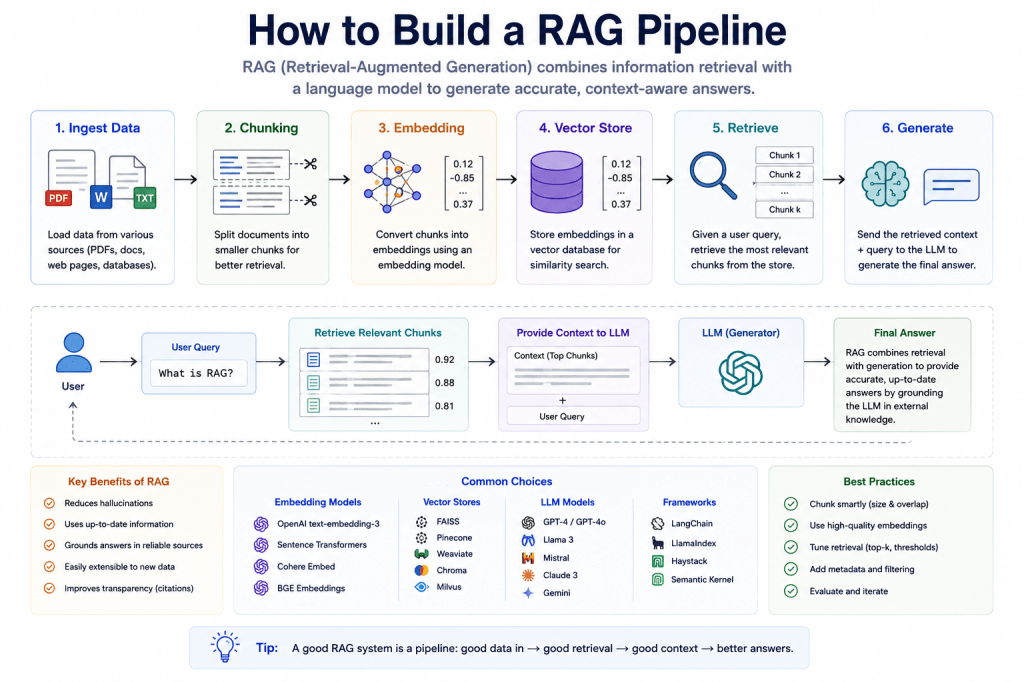
What Is a RAG Pipeline?
A RAG pipeline combines:
- retrieval systems,
- embeddings,
- vector databases,
- and language models
to create AI systems capable of:
- dynamically retrieving knowledge during inference.
Instead of:
answering purely from model weights,
the system:
- retrieves relevant information,
- injects context into prompts,
- and generates grounded responses.
This creates:
- retrieval-augmented reasoning systems.
Related article:
Why RAG Matters
Traditional language models may:
- hallucinate,
- provide outdated information,
- or lack organization-specific knowledge.
RAG solves this by allowing systems to:
- access external documents,
- search internal knowledge,
- and retrieve context dynamically.
This is especially important for:
- enterprise AI,
- reasoning systems,
- and autonomous agents.
Core Components of a RAG Pipeline
Most RAG systems contain several core layers.
Document Loader
Loads:
- PDFs,
- text files,
- websites,
- documentation,
- databases,
- or enterprise knowledge.
Text Chunking
Documents are split into:
- smaller chunks,
- paragraphs,
- or semantic sections.
Chunking improves:
- retrieval precision,
- and embedding quality.
Embedding Model
Each chunk is converted into:
- vector embeddings,
- semantic representations,
- or latent vectors.
This allows:
- semantic similarity search.
Vector Database
Embeddings are stored inside:
- vector databases,
- semantic indexes,
- or retrieval engines.
Examples:
Retriever
The retriever:
- searches embeddings,
- finds relevant chunks,
- and returns contextual information.
Language Model
The LLM receives:
- the user query,
- plus retrieved context.
It then generates:
- grounded responses.
High-Level RAG Workflow
A simplified RAG pipeline looks like this:
- Load documents
- Split text into chunks
- Generate embeddings
- Store embeddings in vector DB
- Receive user query
- Embed query
- Retrieve relevant chunks
- Send context to LLM
- Generate grounded answer
Simple RAG Architecture Diagram
Documents ↓Chunking ↓Embeddings ↓Vector Database ↓Retriever ↓LLM Prompt ↓Generated Answer
Step 1 — Install Required Libraries
A basic Python RAG system can use:
- LangChain,
- FAISS,
- OpenAI embeddings,
- and an LLM provider.
Install dependencies:
pip install langchainpip install faiss-cpupip install openaipip install tiktokenpip install sentence-transformers
You can also use:
- Chroma,
- Ollama,
- Hugging Face models,
- or local embedding systems.
Step 2 — Load Documents
Example:
from langchain.document_loaders import TextLoaderloader = TextLoader("knowledge.txt")documents = loader.load()
You can load:
- PDFs,
- Markdown,
- websites,
- or databases.
Step 3 — Split Documents Into Chunks
Chunking improves:
- retrieval quality,
- embedding relevance,
- and context precision.
Example:
from langchain.text_splitter import RecursiveCharacterTextSplittersplitter = RecursiveCharacterTextSplitter( chunk_size=500, chunk_overlap=50)chunks = splitter.split_documents(documents)
Why Chunking Matters
If chunks are:
- too large → retrieval becomes noisy.
- too small → context becomes fragmented.
Good chunking dramatically improves:
- retrieval performance.
Step 4 — Generate Embeddings
Embeddings convert text into:
- vector representations.
Example:
from langchain.embeddings import OpenAIEmbeddingsembeddings = OpenAIEmbeddings()
Alternative embedding models:
- Sentence Transformers,
- BGE embeddings,
- E5 models,
- Instructor embeddings.
Step 5 — Create the Vector Database
Now store embeddings inside:
- a vector database.
Example using FAISS:
from langchain.vectorstores import FAISSvectorstore = FAISS.from_documents( chunks, embeddings)
This creates:
- semantic search capability.
Step 6 — Create the Retriever
The retriever finds:
- relevant chunks,
- based on semantic similarity.
Example:
retriever = vectorstore.as_retriever()
The retriever returns:
- semantically relevant chunks.
Step 7 — Retrieve Relevant Context
Now retrieve context dynamically.
Example:
query = "What is Chain-of-Thought reasoning?"results = retriever.get_relevant_documents(query)
The retriever returns:
- semantically relevant chunks.
Step 8 — Build the Prompt
Inject retrieved context into the prompt.
Example:
context = "\n".join([doc.page_content for doc in results])prompt = f"""Use the following context:{context}Question:{query}"""
Step 9 — Send to the Language Model
Now generate a grounded response.
Example:
from openai import OpenAIclient = OpenAI()response = client.chat.completions.create( model="gpt-4.1-mini", messages=[ {"role": "user", "content": prompt} ])print(response.choices[0].message.content)
Full Simplified RAG Example
Below is the complete simplified pipeline:
👉 You can experiment with a practical Python implementation of this concept in the official GitHub repository for the Reasoning Systems examples: https://github.com/BenardoKemp/reasoningsystems/tree/main/practical-python/how-to-build-a-rag-pipeline
RAG and AI Agents
RAG is increasingly foundational for:
- AI agents,
- autonomous workflows,
- and enterprise AI systems.
Agents often need to:
- retrieve documents,
- access memory,
- search APIs,
- and maintain contextual awareness.
RAG provides:
- externalized memory for agents.
Related article:
RAG and Workflow Orchestration
Enterprise RAG systems often involve:
- orchestration layers,
- tool routing,
- verifier systems,
- and workflow coordination.
Large systems may combine:
- retrieval,
- planning,
- reflection,
- and verification.
Related article:
RAG and Verifier Models
Advanced RAG systems increasingly use:
- verifier layers,
- reranking systems,
- and retrieval evaluation.
This helps reduce:
- irrelevant retrieval,
- hallucinations,
- and poor grounding.
Related article:
Common Problems in RAG Pipelines
RAG systems introduce several challenges.
Poor Chunking
Bad chunking causes:
- fragmented context,
- retrieval noise,
- or incomplete reasoning.
Weak Embeddings
Poor embedding quality reduces:
- semantic retrieval performance.
Retrieval Drift
The retriever may:
- return irrelevant information,
- or semantically weak matches.
Context Window Limits
Too much retrieved information may:
- overflow context windows,
- or reduce reasoning quality.
Hallucinations
Even with retrieval:
- models may still hallucinate.
This is why:
- verifier systems,
- rerankers,
- and reflection loops
are increasingly important.
Advanced RAG Architectures
Modern RAG systems increasingly explore:
- agentic RAG,
- multimodal RAG,
- graph RAG,
- hierarchical retrieval,
- and adaptive retrieval systems.
Future RAG pipelines may become:
- dynamic reasoning ecosystems,
- rather than simple retrieval layers.
Practical Applications
RAG pipelines are increasingly important for:
- enterprise AI,
- document assistants,
- coding systems,
- customer support,
- research assistants,
- legal AI,
- and autonomous agents.
Applications requiring:
- grounded reasoning,
- contextual memory,
- or enterprise knowledge
often depend heavily on RAG architectures.
RAG Pipelines and the Future of AI
RAG represents one of the most important transitions in modern AI systems.
The industry is increasingly moving from:
static memorization systems
toward:
dynamic reasoning systems capable of retrieving and integrating external knowledge during inference.
This transition is influencing:
- reasoning architectures,
- enterprise AI,
- autonomous agents,
- and intelligent workflow systems.
RAG pipelines are increasingly viewed as:
one of the foundational architectures behind grounded AI systems.
Related Concepts
- Retrieval-Augmented Reasoning
- Memory Architectures
- AI Agents
- Workflow Orchestration
- Embeddings
- Vector Databases
- Verifier Models
- Autonomous Workflows
- Deliberative Inference
- Tool Calling
Continue Exploring
To continue exploring reasoning architectures and retrieval systems, consider reading:
- Retrieval-Augmented Reasoning Explained
- Memory Architectures for AI Agents
- Workflow Orchestration in AI Systems
- What Are Verifier Models?
- Autonomous Workflows Explained
These concepts build directly on the foundations introduced by RAG pipelines.
