Neural networks are often associated with advanced AI systems, large language models, and image generation. But underneath all of that complexity lies a surprisingly simple foundation: learning mathematical relationships from data.
One of the best beginner exercises in PyTorch is teaching a neural network how to add two numbers.
It may sound trivial, but this small example demonstrates many of the core mechanisms behind deep learning systems:
- Forward propagation
- Hidden representations
- Loss calculation
- Gradient descent
- Backpropagation
- Weight updates
- Generalization to unseen data
In this article, we will build a complete PyTorch program that learns addition from examples.
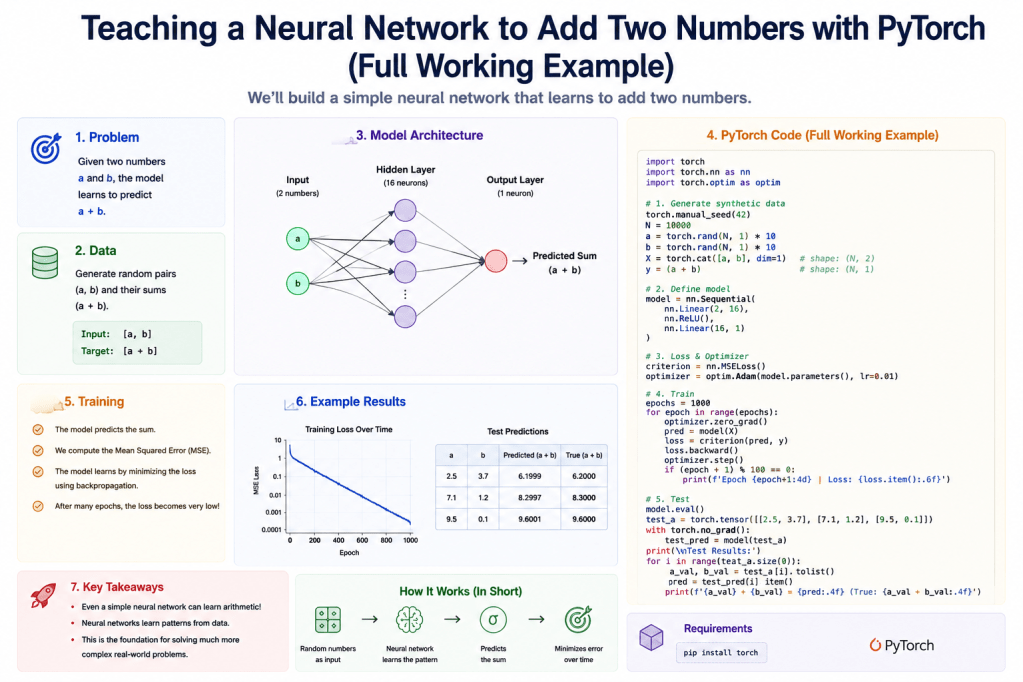
What Are We Trying to Teach?
We want a neural network to learn this relationship:
y=x1+x2
Instead of manually programming addition logic, we allow the neural network to discover the pattern from training examples.
The model will observe examples such as:
| Input | Output |
|---|---|
| 1 + 2 | 3 |
| 2 + 3 | 5 |
| 5 + 6 | 11 |
Over time, the model adjusts internal weights until it can correctly predict sums for numbers it has never seen before.
Why This Example Matters
Although adding two numbers is simple for humans, this example introduces nearly every important concept in neural network training.
A neural network does not “understand” addition symbolically like a calculator. Instead, it approximates numerical relationships through learned parameters.
This same learning mechanism scales into:
- Image recognition
- Language translation
- AI agents
- Recommendation systems
- Transformer architectures
- Reasoning models
Understanding this small example builds intuition for much larger systems.
Full Working PyTorch Code
Below is the complete working program.
You can copy this directly into a Python file such as:
add_two_numbers_with_pytorch.py
and run it immediately.
👉 You can experiment with a practical Python implementation of this concept in the official GitHub repository for the Reasoning Systems examples: https://github.com/BenardoKemp/reasoningsystems/tree/main/practical-python/add-two-numbers-with-pytorch
Step-by-Step Breakdown
1. Importing PyTorch
import torchimport torch.nn as nnimport torch.optim as optim
These imports provide:
- Tensor operations
- Neural network layers
- Optimization algorithms
PyTorch tensors are similar to NumPy arrays but support automatic differentiation and GPU acceleration.
2. Creating the Training Data
X = torch.tensor([ [1.0, 2.0], [2.0, 3.0], ...])
Each row contains two input numbers.
The targets are:
y = torch.tensor([ [3.0], [5.0], ...])
which represent the correct sums.
The neural network will try to learn the mapping:
Input → Correct Output
3. Building the Neural Network
model = nn.Sequential( nn.Linear(2, 8), nn.ReLU(), nn.Linear(8, 1))
This architecture contains:
| Layer | Purpose |
|---|---|
| Linear(2,8) | Converts 2 inputs into 8 learned features |
| ReLU | Adds non-linearity |
| Linear(8,1) | Produces the final prediction |
The hidden layer computes an intermediate representation:
h=ReLU(Wx+b)
This is where the network internally learns numerical relationships.
4. Loss Function
The loss function measures prediction error.
criterion = nn.MSELoss()
Mean Squared Error computes:
MSE=n1∑i=1n(yi−y^i)2
Smaller loss values mean better predictions.
The goal of training is to minimize this error.
5. Optimizer
optimizer = optim.Adam(model.parameters(), lr=0.01)
Adam is a popular optimization algorithm that updates model weights efficiently.
The optimizer adjusts the neural network parameters after every training step.
6. Training Loop
The training loop repeatedly shows data to the model.
for epoch in range(epochs):
Each epoch performs:
- Forward pass
- Loss calculation
- Gradient computation
- Weight update
Forward Pass
predictions = model(X)
Compute Error
loss = criterion(predictions, y)
The model compares predictions to correct answers.
Clear Old Gradients
optimizer.zero_grad()
Backpropagation
loss.backward()
PyTorch automatically computes gradients using automatic differentiation.
This is one of the most important mechanisms in deep learning.
Update Weights
optimizer.step()
The optimizer adjusts parameters to reduce error.
Over many iterations, the model improves.
7. Testing the Model
After training, we test the network on unseen data.
test_input = torch.tensor([[10.0, 15.0]])
Expected answer:
25
The network predicts a value close to this despite never seeing the example before.
This ability to generalize is central to machine learning.
Example Output
You may see output similar to:
Epoch 0, Loss: 58.231247Epoch 200, Loss: 0.341912Epoch 400, Loss: 0.021457Epoch 600, Loss: 0.002194Test Result------------------Input Numbers : 10 and 15Predicted Sum : 24.99
The decreasing loss shows that the network is learning.
What Is Actually Happening Internally?
The neural network learns parameters that approximate addition behavior.
Internally, the model performs operations like:
The weights gradually shift until predictions become accurate.
The network is not explicitly programmed with arithmetic rules.
Instead, it statistically approximates the relationship between inputs and outputs.
Why Use a Neural Network for Addition?
In practice, you would never use a neural network to perform basic arithmetic.
A calculator is faster, exact, and more efficient.
However, this example is valuable because it demonstrates:
- How neural networks learn
- How training loops work
- How gradients update parameters
- How loss minimization functions
- How generalization emerges
This is foundational knowledge for:
- Deep learning
- LLMs
- Computer vision
- Reinforcement learning
- AI reasoning systems
Next Steps
Once you understand this example, you can extend it into:
More Complex Arithmetic
- Subtraction
- Multiplication
- Division
Sequence-Based Reasoning
Teach the model step-by-step arithmetic.
Transformer-Based Numerical Reasoning
Token-based arithmetic similar to language models.
Chain-of-Thought Reasoning
Intermediate reasoning steps before final answers.
Symbolic + Neural Hybrid Systems
Combining neural networks with explicit reasoning logic.
Final Thoughts
Teaching a neural network to add two numbers may appear simple, but it reveals the mechanics behind modern AI systems.
At its core, deep learning is about discovering patterns through optimization.
Even advanced reasoning models begin with the same underlying principles:
- Inputs
- Hidden representations
- Loss functions
- Gradient updates
- Iterative learning
Mastering these fundamentals makes larger neural architectures far easier to understand.
