As AI systems become increasingly capable at:
- answering questions,
- solving benchmarks,
- and generating convincing explanations,
researchers are asking a deeper question:
Can AI systems reason through genuinely difficult expert-level problems?
Many traditional benchmarks are becoming:
- saturated,
- memorized,
- or too easy for frontier models.
Researchers therefore need evaluations that test:
- advanced reasoning,
- scientific understanding,
- abstraction,
- and expert-level problem solving.
One of the most important benchmarks designed for this purpose is:
GPQA.
GPQA is becoming increasingly important for evaluating:
- reasoning models,
- scientific AI systems,
- advanced language models,
- and frontier reasoning architectures.
Unlike many conventional benchmarks, GPQA focuses heavily on:
difficult expert-level reasoning rather than simple factual recall.
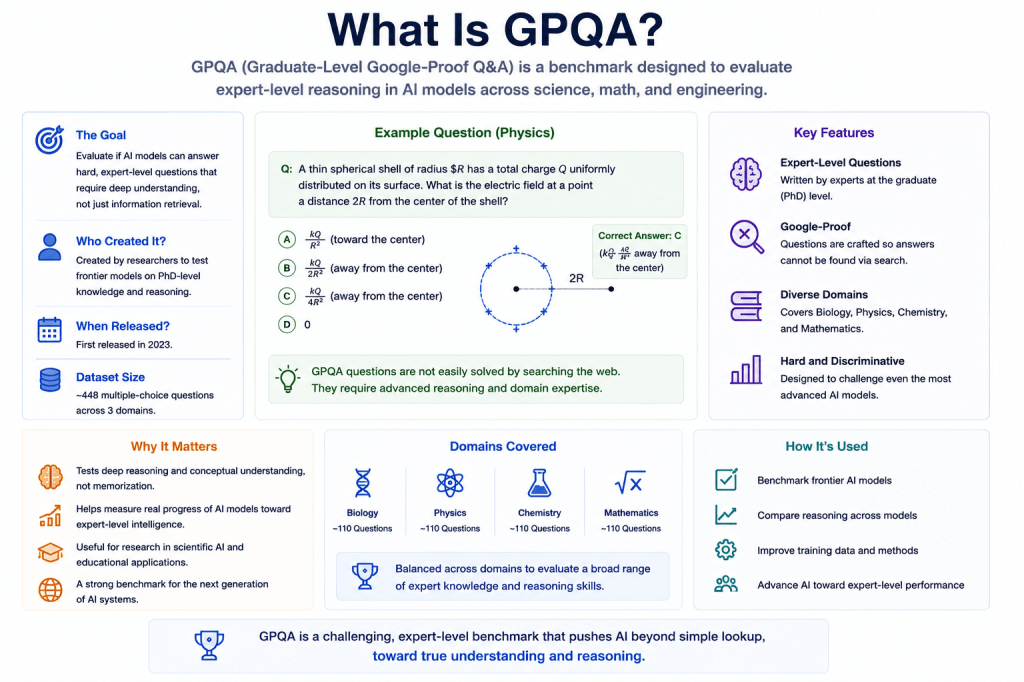
What Does GPQA Mean?
GPQA stands for:
Graduate-Level Google-Proof Q&A.
The benchmark is designed to evaluate whether AI systems can answer:
- highly difficult,
- expert-level,
- domain-specific questions
that are intentionally difficult to solve through:
- shallow memorization,
- internet search,
- or pattern matching.
The benchmark focuses heavily on:
- scientific reasoning,
- expert knowledge,
- and multi-step analytical thinking.
Why GPQA Matters
Many AI benchmarks measure:
- broad factual knowledge,
- language understanding,
- or standard reasoning tasks.
However, frontier AI systems increasingly perform extremely well on:
- common benchmark datasets.
This creates a major problem:
benchmark saturation.
Models may:
- memorize patterns,
- exploit benchmark shortcuts,
- or overfit to evaluation datasets.
GPQA was designed to reduce these issues by focusing on:
- difficult expert-level questions,
- and deeper reasoning requirements.
This makes it highly relevant for:
- evaluating frontier reasoning capability.
Why It Is Called “Google-Proof”
GPQA questions are intentionally designed to be:
- difficult to answer through simple web search,
- or shallow retrieval.
The benchmark attempts to evaluate:
actual reasoning and expertise,
rather than:
information lookup ability.
This becomes increasingly important as AI systems gain:
- retrieval access,
- internet connectivity,
- and tool usage.
What Types of Questions Exist in GPQA?
GPQA often includes:
- advanced scientific reasoning,
- biology,
- chemistry,
- physics,
- and expert-level analytical questions.
The problems frequently require:
- conceptual understanding,
- multi-step reasoning,
- domain expertise,
- and careful inference.
Simple memorization is often insufficient.
Why GPQA Is Difficult for AI Systems
GPQA is difficult because it combines:
- advanced knowledge,
- reasoning depth,
- and low shortcut availability.
Many questions require:
- structured analysis,
- elimination reasoning,
- intermediate inference,
- and conceptual understanding.
This makes GPQA highly relevant for:
- reasoning-oriented AI research.
GPQA vs Traditional Benchmarks
The distinction is important.
Traditional Benchmarks
Many benchmarks focus on:
- broad knowledge,
- standard QA,
- or common reasoning tasks.
These benchmarks often become vulnerable to:
- memorization,
- contamination,
- and benchmark saturation.
GPQA
GPQA instead focuses on:
- difficult expert reasoning,
- conceptual analysis,
- and low-shortcut evaluation.
This makes it much harder for systems to:
- rely purely on memorized patterns.
GPQA and Reasoning Systems
GPQA strongly rewards:
- structured reasoning,
- careful inference,
- and analytical problem solving.
Reactive systems often struggle because:
- the questions require:
- deliberation,
- decomposition,
- and conceptual reasoning.
Modern reasoning architectures increasingly use:
- Chain-of-Thought reasoning,
- reflection,
- verifier systems,
- and deliberative inference
to improve GPQA performance.
Related articles:
GPQA and Chain-of-Thought Reasoning
Step-by-step reasoning often improves GPQA performance significantly.
Instead of:
immediate answer generation,
the model may:
- analyze evidence,
- compare alternatives,
- reason sequentially,
- and evaluate intermediate conclusions.
This helps reduce:
- shallow reasoning errors,
- and conceptual mistakes.
Related article:
GPQA and Reflection Systems
Reflection systems may:
- critique reasoning,
- identify inconsistencies,
- revise interpretations,
- and improve answers iteratively.
Expert-level reasoning often benefits heavily from:
- self-correction,
- and reasoning revision.
Related article:
GPQA and Verifier Models
Verifier architectures are especially important for:
- scientific reasoning benchmarks.
Verifier systems may:
- inspect intermediate logic,
- validate conclusions,
- detect inconsistencies,
- and evaluate reasoning quality.
This improves:
- analytical robustness,
- and reasoning reliability.
Related article:
GPQA and Test-Time Compute
GPQA performance often improves significantly when models allocate:
- more inference-time reasoning,
- deeper deliberation,
- and additional analysis.
Instead of:
one-pass prediction,
the system may:
- deliberate longer,
- explore alternatives,
- and revise reasoning dynamically.
This strongly connects GPQA with:
- test-time compute scaling.
Related article:
GPQA and Deliberative Inference
GPQA tasks often benefit from:
- deliberative reasoning architectures.
The system may:
- evaluate hypotheses,
- compare interpretations,
- analyze evidence,
- and refine conclusions iteratively.
This improves:
- expert-level reasoning quality.
Related article:
GPQA and Autonomous Agents
Advanced agents increasingly require:
- scientific reasoning,
- analytical planning,
- and adaptive inference.
GPQA provides useful insights into:
- whether autonomous systems can reason through:
- difficult expert-level tasks.
This becomes increasingly important for:
- scientific AI,
- enterprise reasoning systems,
- and advanced autonomous workflows.
Related article:
GPQA and Benchmark Contamination
One reason GPQA became important is concern over:
benchmark contamination.
Large models may inadvertently:
- memorize benchmark data,
- or learn benchmark patterns during training.
GPQA attempts to reduce this problem by:
- using difficult expert-created questions,
- and minimizing shortcut opportunities.
This makes it more valuable for evaluating:
- true reasoning capability.
GPQA and Generalization
GPQA strongly tests:
- reasoning under uncertainty,
- conceptual understanding,
- and generalization ability.
The benchmark attempts to evaluate:
- whether systems can reason beyond memorized training patterns.
This is one of the central challenges of modern AI research.
Limitations of GPQA
Although highly valuable, GPQA also has limitations.
Potential criticisms include:
- limited domain coverage,
- expert bias,
- benchmark overfitting,
- or evaluation subjectivity.
Additionally:
- strong GPQA performance does not necessarily imply:
- AGI,
- or universal reasoning capability.
However, the benchmark remains extremely important because it focuses heavily on:
- difficult reasoning,
- rather than shallow recall.
Emerging Trends Around GPQA
Modern reasoning systems increasingly explore:
- reflection-driven inference,
- verifier-guided reasoning,
- search-based reasoning,
- adaptive planning,
- and multi-agent analysis
to improve GPQA performance.
Future AI systems may increasingly depend on:
- structured reasoning architectures,
- rather than static memorization systems.
Practical Importance of GPQA
GPQA is increasingly important for:
- frontier AI evaluation,
- reasoning research,
- scientific AI systems,
- benchmark analysis,
- and cognitive AI research.
Researchers frequently use GPQA to evaluate:
- analytical depth,
- reasoning quality,
- conceptual understanding,
- and expert-level inference capability.
This makes GPQA one of the most important benchmarks for:
- advanced reasoning AI systems.
Python Example: Simplified GPQA Reasoning Workflow
Below is a simplified conceptual example.
question = load_gpqa_question()analysis = generate_reasoning_trace(question)verified_answer = evaluate_reasoning(analysis)print(verified_answer)
Real GPQA systems often involve:
- reflection architectures,
- verifier systems,
- deliberative inference,
- and multi-step reasoning pipelines.
GPQA and the Future of AI
GPQA represents one of the most important transitions in AI evaluation.
The industry is increasingly moving from:
shallow benchmark evaluation
toward:
expert-level reasoning assessment focused on conceptual understanding and analytical depth.
This transition is influencing:
- reasoning architectures,
- scientific AI,
- autonomous agents,
- and cognitive AI research.
GPQA is increasingly viewed as:
one of the foundational benchmarks behind advanced reasoning evaluation.
Related Concepts
- Chain-of-Thought Reasoning
- Reflection Systems
- Verifier Models
- Deliberative Inference
- Test-Time Compute
- ARC-AGI
- GSM8K
- Process Supervision
- Reasoning Traces
- Autonomous Agents
Continue Exploring
To continue exploring reasoning benchmarks and architectures, consider reading:
- What Is ARC-AGI?
- What Is GSM8K?
- Reflection Loops in AI Systems
- Deliberative Inference Explained
- What Are Verifier Models?
These concepts build directly on the reasoning foundations evaluated by GPQA.
👉 You can experiment with a practical Python implementation of this concept in the official GitHub repository for the Reasoning Systems examples:
