As AI systems become increasingly capable at:
- writing code,
- debugging software,
- fixing bugs,
- and assisting developers,
researchers need reliable ways to evaluate:
whether AI can actually perform real-world software engineering tasks.
Traditional coding benchmarks often focus on:
- short code snippets,
- isolated programming questions,
- or simplified algorithmic tasks.
However, real software engineering is much more complex.
Modern coding systems must often:
- understand repositories,
- navigate dependencies,
- modify existing code,
- run tests,
- debug failures,
- and coordinate multi-step workflows.
One of the most important benchmarks designed to evaluate these capabilities is:
SWE-bench.
SWE-bench is rapidly becoming one of the foundational benchmarks for:
- AI coding agents,
- autonomous software engineering,
- reasoning systems,
- and real-world coding evaluation.
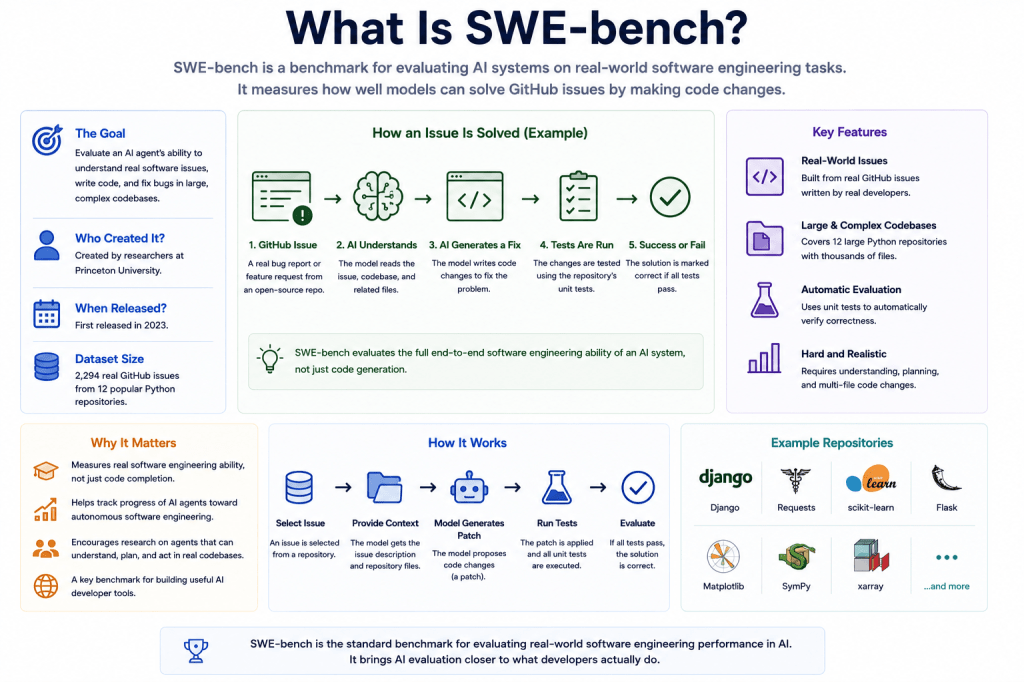
What Does SWE-bench Mean?
SWE stands for:
Software Engineering.
SWE-bench is a benchmark designed to evaluate whether AI systems can:
- solve real GitHub issues,
- modify existing repositories,
- and produce working software fixes.
Instead of:
toy coding exercises,
SWE-bench focuses on:
- realistic software engineering workflows.
The benchmark evaluates:
- reasoning,
- debugging,
- repository understanding,
- and autonomous coding capability.
Why SWE-bench Matters
Many AI coding systems perform well on:
- isolated coding tasks,
- interview-style problems,
- or short algorithmic exercises.
However, real software engineering requires:
- understanding large codebases,
- navigating dependencies,
- debugging failures,
- and coordinating workflows.
SWE-bench attempts to measure:
whether AI systems can function more like real software engineers.
This makes it highly important for:
- coding agents,
- autonomous development systems,
- and enterprise AI engineering workflows.
The Core Idea Behind SWE-bench
SWE-bench evaluates AI systems using:
- real GitHub issues,
- from real repositories.
The AI system typically receives:
- repository context,
- issue descriptions,
- codebase structure,
- and test environments.
The system must then:
- understand the issue,
- identify relevant files,
- modify code correctly,
- and produce a valid software fix.
The solution is evaluated using:
- automated testing,
- repository validation,
- and execution correctness.
Why SWE-bench Is Difficult
SWE-bench is difficult because it requires much more than:
- code generation.
The system must often:
- understand large repositories,
- maintain context,
- reason about architecture,
- debug failures,
- and coordinate multiple changes.
This introduces challenges involving:
- planning,
- memory,
- retrieval,
- and long-horizon reasoning.
Simple reactive models often fail because:
- real software engineering requires structured workflows.
SWE-bench and AI Agents
SWE-bench is closely connected to:
AI agents.
Modern coding agents increasingly attempt to:
- navigate repositories,
- plan fixes,
- run tests,
- revise implementations,
- and iterate autonomously.
SWE-bench evaluates many of the capabilities required for:
- autonomous software engineering systems.
Related article:
SWE-bench and Planning Systems
Coding tasks often require:
- multi-step planning,
- dependency analysis,
- and structured execution.
A system may need to:
- identify relevant files,
- understand architecture,
- design modifications,
- run tests,
- debug failures,
- and revise solutions.
Planning systems are therefore highly relevant to SWE-bench performance.
Related article:
SWE-bench and Task Decomposition
Software engineering problems are often too large for:
single-step inference.
Successful systems frequently use:
- task decomposition,
- workflow segmentation,
- and hierarchical reasoning.
The system may divide problems into:
- retrieval tasks,
- debugging tasks,
- implementation tasks,
- and verification tasks.
Related article:
SWE-bench and Retrieval-Augmented Reasoning
Coding systems often rely heavily on:
- retrieval architectures.
The system may retrieve:
- repository files,
- documentation,
- API references,
- test outputs,
- and prior implementations.
This creates:
- retrieval-augmented coding systems.
Without retrieval, models struggle with:
- repository-scale reasoning.
Related article:
SWE-bench and Memory Architectures
Real software engineering requires:
- persistent contextual memory.
The system may need to remember:
- prior file modifications,
- debugging history,
- architecture decisions,
- and workflow state.
Memory systems dramatically improve:
- coding continuity,
- and long-horizon reasoning.
Related article:
SWE-bench and Tool Calling
Coding agents often depend heavily on:
- tools,
- execution environments,
- and repository operations.
Examples:
- running tests,
- executing Python,
- inspecting files,
- using linters,
- or interacting with Git.
Tool use is one of the defining capabilities behind:
- autonomous coding systems.
Related article:
SWE-bench and Workflow Orchestration
Real coding workflows require:
- orchestration,
- coordination,
- and adaptive execution.
A coding workflow may involve:
- retrieval,
- planning,
- code generation,
- testing,
- debugging,
- and verification.
Workflow orchestration helps systems:
- coordinate execution reliably.
Related article:
SWE-bench and Reflection Systems
Reflection systems are increasingly important for:
- debugging,
- code revision,
- and iterative improvement.
A reflective coding system may:
- generate code,
- run tests,
- analyze failures,
- revise implementation,
- and retry execution.
This significantly improves:
- autonomous debugging capability.
Related article:
SWE-bench and Verifier Models
Verifier systems may:
- inspect outputs,
- validate patches,
- evaluate tests,
- and detect implementation errors.
Verification becomes especially important because:
- generated code may appear plausible while still failing operationally.
Related article:
SWE-bench and Test-Time Compute
Complex coding tasks often benefit heavily from:
- increased reasoning depth,
- iterative refinement,
- and additional inference computation.
Instead of:
immediate code generation,
systems may:
- deliberate,
- retrieve context,
- revise implementations,
- and evaluate alternatives.
This strongly connects SWE-bench with:
- test-time compute scaling.
Related article:
SWE-bench and Multi-Agent Systems
Some advanced coding systems distribute software engineering tasks across:
- planner agents,
- coding agents,
- verifier agents,
- retrieval agents,
- and orchestration agents.
This creates:
- collaborative coding architectures.
Multi-agent systems may improve:
- specialization,
- scalability,
- and debugging reliability.
Related article:
Why SWE-bench Is Important
SWE-bench is increasingly viewed as:
one of the strongest benchmarks for evaluating real-world AI coding capability.
Unlike simplified programming benchmarks, SWE-bench measures:
- repository reasoning,
- workflow coordination,
- debugging ability,
- and autonomous software engineering performance.
This makes it highly relevant to:
- enterprise AI,
- coding agents,
- and autonomous development systems.
Limitations of SWE-bench
Although influential, SWE-bench also has limitations.
Potential challenges include:
- benchmark overfitting,
- repository selection bias,
- evaluation complexity,
- and operational reproducibility.
Additionally:
- strong SWE-bench performance does not necessarily imply:
- general intelligence,
- or universal software engineering mastery.
However, the benchmark remains extremely valuable because it focuses on:
- realistic coding workflows,
- rather than isolated code generation.
Emerging Trends Around SWE-bench
Modern coding systems increasingly explore:
- autonomous debugging,
- repository-aware reasoning,
- reflection-driven coding,
- retrieval-enhanced development,
- and multi-agent software engineering.
Future AI coding systems may increasingly function as:
- autonomous engineering platforms,
- rather than simple code generators.
Practical Importance of SWE-bench
SWE-bench is increasingly important for:
- AI coding evaluation,
- autonomous software engineering,
- coding agent research,
- enterprise AI development,
- and reasoning system evaluation.
Researchers frequently use SWE-bench to evaluate:
- coding reliability,
- debugging capability,
- workflow coordination,
- and repository reasoning.
This makes SWE-bench one of the foundational benchmarks behind:
- autonomous coding AI systems.
Python Example: Simplified SWE-bench Workflow
Below is a simplified conceptual example.
issue = load_github_issue()repository = retrieve_repository_context(issue)plan = create_fix_plan(issue)patch = generate_code_fix(plan)run_tests(patch)
Real SWE-bench systems often involve:
- orchestration frameworks,
- retrieval pipelines,
- reflection loops,
- and verifier architectures.
SWE-bench and the Future of AI
SWE-bench represents one of the most important transitions in AI evaluation.
The industry is increasingly moving from:
isolated coding benchmarks
toward:
realistic software engineering evaluation involving repositories, workflows, debugging, and autonomous execution.
This transition is influencing:
- coding agents,
- reasoning architectures,
- autonomous workflows,
- enterprise AI,
- and software engineering research.
SWE-bench is increasingly viewed as:
one of the foundational benchmarks behind autonomous coding intelligence.
Related Concepts
- AI Agents
- Planning Systems
- Task Decomposition
- Workflow Orchestration
- Retrieval-Augmented Reasoning
- Reflection Systems
- Verifier Models
- Test-Time Compute
- Autonomous Workflows
- Multi-Agent Systems
Continue Exploring
To continue exploring reasoning architectures and coding systems, consider reading:
- What Are AI Agents?
- Reflection Loops in AI Systems
- Workflow Orchestration in AI Systems
- Retrieval-Augmented Reasoning Explained
- Multi-Agent Systems Explained
These concepts build directly on the foundations evaluated by SWE-bench.
👉 You can experiment with a practical Python implementation of this concept in the official GitHub repository for the Reasoning Systems examples:
