As AI systems evolve from:
- simple chatbots,
- isolated language models,
- and static prediction systems
into:
- autonomous agents,
- workflow coordinators,
- coding systems,
- and reasoning architectures,
a major challenge is becoming increasingly important:
How do we evaluate AI agents reliably?
Traditional AI evaluation often focuses on:
- benchmark accuracy,
- single-answer correctness,
- or static task performance.
However, autonomous agents introduce entirely new challenges involving:
- planning,
- memory,
- tool use,
- workflow execution,
- long-horizon reasoning,
- and adaptive coordination.
Evaluating AI agents therefore requires much more than:
measuring final answers.
This is becoming one of the most important research areas in:
- reasoning AI,
- autonomous systems,
- enterprise AI,
- and AGI evaluation.
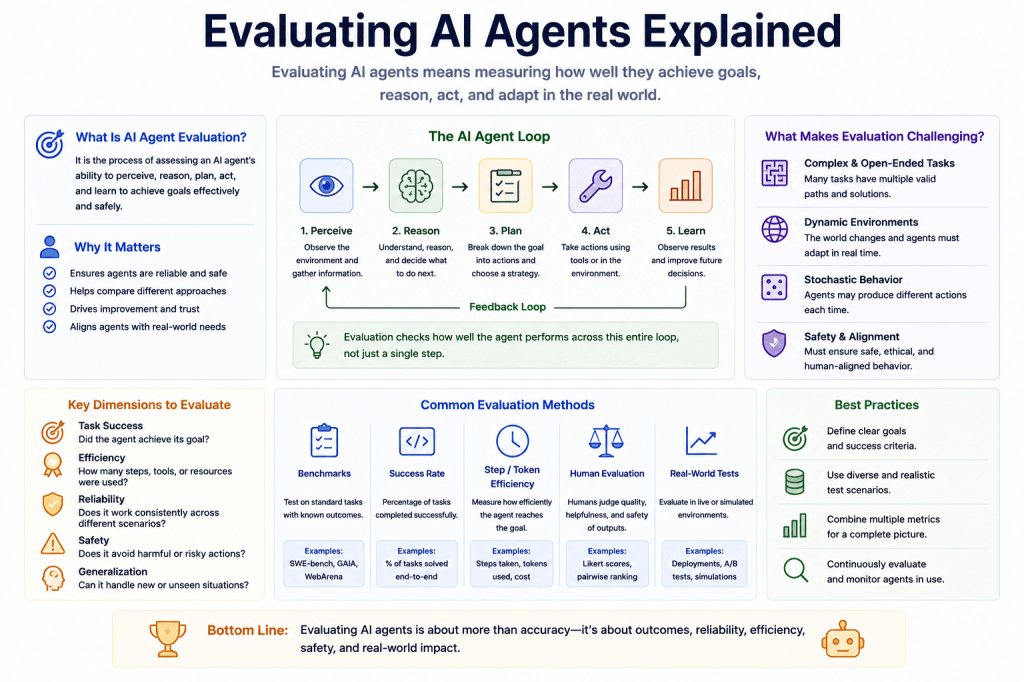
Why Evaluating AI Agents Is Difficult
Traditional language models are often evaluated using:
- fixed datasets,
- static prompts,
- and predefined answers.
AI agents are fundamentally different.
Agents may:
- plan dynamically,
- interact with environments,
- coordinate tools,
- revise workflows,
- and adapt continuously during execution.
This creates evaluation challenges involving:
- non-determinism,
- long workflows,
- environmental interaction,
- and evolving state.
Agent evaluation therefore becomes:
much more complex than standard model evaluation.
What Does “Good Agent Performance” Mean?
An AI agent may need to:
- complete tasks,
- coordinate workflows,
- adapt to failures,
- manage memory,
- use tools safely,
- and maintain long-term objectives.
This means evaluation may involve:
- correctness,
- reliability,
- efficiency,
- safety,
- robustness,
- and coordination quality.
Unlike simple QA systems, agents must often be evaluated across:
- complete workflows,
- not isolated outputs.
A Simple Example
Imagine two AI coding agents.
Agent A
- generates code quickly,
- but introduces hidden bugs,
- ignores failed tests,
- and loses workflow state.
Agent B
- reasons more carefully,
- revises failures,
- maintains planning continuity,
- and validates outputs before execution.
Even if both produce:
similar final answers,
Agent B is often:
- operationally superior.
This illustrates why agent evaluation must measure:
- process quality,
- not just outcome quality.
Traditional Benchmark Evaluation vs Agent Evaluation
The distinction is increasingly important.
Traditional Benchmark Evaluation
Focuses on:
- static datasets,
- accuracy,
- and final-answer correctness.
Examples:
- multiple-choice benchmarks,
- question-answer datasets,
- standard reasoning tasks.
Agent Evaluation
Focuses on:
- workflow execution,
- planning quality,
- tool coordination,
- memory usage,
- adaptation,
- and long-horizon reasoning.
This creates:
- dynamic evaluation systems.
Core Dimensions of AI Agent Evaluation
Modern agent evaluation often combines multiple dimensions.
Task Completion
Did the agent:
- complete the objective successfully?
This remains important but is:
- no longer sufficient alone.
Planning Quality
Did the agent:
- organize workflows logically,
- decompose tasks effectively,
- and sequence actions coherently?
Related article:
Tool Use Reliability
Did the agent:
- invoke tools correctly,
- manage APIs safely,
- and avoid operational failures?
Related article:
Memory Management
Did the agent:
- maintain continuity,
- track objectives,
- and preserve workflow state properly?
Related article:
- Memory Architectures for AI Agents
Adaptation and Recovery
Could the agent:
- recover from failures,
- revise strategies,
- and adapt dynamically?
Related article:
Long-Horizon Coordination
Could the agent maintain:
- coherent execution,
- across extended workflows?
This is one of the defining challenges of autonomous systems.
Safety and Reliability
Did the agent:
- behave safely,
- avoid harmful actions,
- and maintain operational constraints?
This is becoming critically important for:
- enterprise AI,
- and autonomous workflows.
Agent Evaluation and Reasoning Systems
Reasoning quality is central to:
- autonomous agent performance.
Modern agents increasingly rely on:
- Chain-of-Thought reasoning,
- reflection,
- deliberative inference,
- and verifier systems.
Evaluating reasoning quality therefore becomes increasingly important for:
- agent evaluation itself.
Related articles:
Agent Evaluation and Process Supervision
Process supervision is highly relevant for:
- evaluating autonomous agents.
Instead of evaluating only:
final outputs,
systems may evaluate:
- intermediate reasoning,
- planning traces,
- and workflow execution quality.
This improves:
- interpretability,
- oversight,
- and reliability assessment.
Related article:
Agent Evaluation and Reasoning Traces
Reasoning traces help evaluators:
- inspect planning,
- analyze decisions,
- diagnose failures,
- and understand workflow behavior.
Without reasoning traces:
- many agent failures remain difficult to analyze.
Related article:
Agent Evaluation and Multi-Agent Systems
Multi-agent systems introduce even more complexity.
Evaluators may need to assess:
- communication quality,
- coordination reliability,
- shared memory consistency,
- and collaborative reasoning.
This creates:
- distributed evaluation challenges.
Related article:
- Multi-Agent Systems Explained
Agent Evaluation and Workflow Orchestration
Workflow orchestration becomes increasingly important in:
- enterprise agent systems.
Evaluation may involve:
- execution order,
- workflow stability,
- retry behavior,
- dependency coordination,
- and state synchronization.
Related article:
Agent Evaluation and Benchmark Design
Traditional static benchmarks are increasingly insufficient for:
- autonomous systems.
Modern evaluation increasingly explores:
- interactive tasks,
- simulated environments,
- dynamic workflows,
- and real-world execution scenarios.
This is becoming one of the biggest shifts in:
- reasoning AI evaluation.
Agent Evaluation and SWE-bench
SWE-bench became influential partly because it evaluates:
- realistic workflow behavior,
- repository reasoning,
- debugging,
- and software engineering coordination.
This makes it more aligned with:
- agent-style evaluation.
Related article:
- What Is SWE-bench?
Agent Evaluation and ARC-AGI
ARC-AGI evaluates:
- adaptive reasoning,
- abstraction,
- and generalization.
These capabilities are increasingly important for:
- autonomous agents operating in unfamiliar environments.
Related article:
Challenges of Evaluating AI Agents
Agent evaluation introduces major research challenges.
Potential problems include:
- non-deterministic behavior,
- workflow variability,
- hidden reasoning,
- long-horizon instability,
- and dynamic environmental interaction.
Agents may:
- partially succeed,
- fail silently,
- or behave inconsistently across executions.
This makes evaluation:
- expensive,
- complex,
- and difficult to standardize.
Agent Evaluation and AI Safety
Agent evaluation is increasingly critical for:
- AI safety,
- governance,
- and operational oversight.
As agents gain:
- autonomy,
- execution capability,
- and environmental access,
society must increasingly evaluate:
- reliability,
- controllability,
- and safe operational behavior.
This is becoming one of the defining challenges of:
- autonomous AI systems.
Emerging Trends in Agent Evaluation
The field is evolving rapidly.
Modern systems increasingly explore:
- simulation-based evaluation,
- adversarial testing,
- interactive benchmarks,
- long-horizon task assessment,
- and environment-aware evaluation.
Future AI evaluation may increasingly resemble:
- operational systems testing,
- rather than static benchmark scoring.
Practical Importance of Agent Evaluation
Evaluating AI agents is increasingly important for:
- enterprise AI,
- coding systems,
- autonomous workflows,
- robotics,
- cybersecurity,
- research automation,
- and intelligent operations systems.
Organizations increasingly need to determine:
- whether agents are:
- reliable,
- safe,
- adaptive,
- and operationally trustworthy.
Python Example: Simplified Agent Evaluation Workflow
Below is a simplified conceptual example.
task = load_agent_task()execution_trace = run_agent(task)evaluation = assess_workflow(execution_trace)print(evaluation)
Real agent evaluation systems often involve:
- simulation environments,
- verifier models,
- reflection analysis,
- and orchestration monitoring.
Evaluating AI Agents and the Future of AI
Evaluating AI agents represents one of the most important challenges in modern artificial intelligence.
The industry is increasingly moving from:
static model evaluation
toward:
dynamic evaluation of autonomous reasoning systems operating across real-world workflows and environments.
This transition is influencing:
- reasoning architectures,
- enterprise AI,
- autonomous systems,
- AI safety research,
- and AGI evaluation.
Agent evaluation is increasingly viewed as:
one of the foundational requirements behind trustworthy autonomous AI systems.
Related Concepts
- AI Agents
- Planning Systems
- Process Supervision
- Reasoning Traces
- Workflow Orchestration
- Reflection Systems
- Multi-Agent Systems
- SWE-bench
- ARC-AGI
- Test-Time Compute
Continue Exploring
To continue exploring reasoning architectures and evaluation systems, consider reading:
- Process Supervision Explained
- What Is SWE-bench?
- Workflow Orchestration in AI Systems
- Reflection Loops in AI Systems
- What Is ARC-AGI?
These concepts build directly on the challenges involved in evaluating autonomous AI agents.
👉 You can experiment with a practical Python implementation of this concept in the official GitHub repository for the Reasoning Systems examples:
