One of the biggest limitations of traditional AI models is that they rely heavily on:
- static training data,
- fixed model parameters,
- and internal memorization.
This creates major problems.
AI systems may:
- hallucinate information,
- provide outdated answers,
- forget critical details,
- or struggle with domain-specific knowledge.
Modern AI architectures increasingly address these limitations through:
retrieval-augmented reasoning.
Retrieval-Augmented Reasoning combines:
- reasoning systems,
- memory architectures,
- and external retrieval mechanisms
to create AI systems capable of:
- accessing external knowledge,
- grounding reasoning in real data,
- and dynamically incorporating information during inference.
This approach is becoming foundational to:
- AI agents,
- enterprise AI,
- coding systems,
- research workflows,
- and autonomous reasoning architectures.
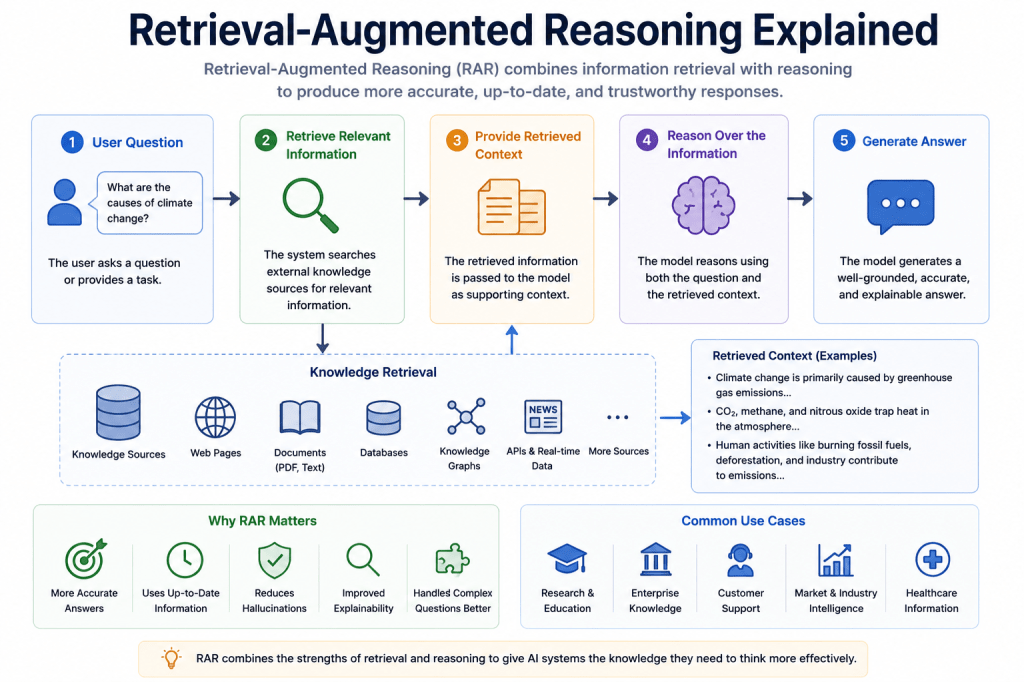
What Is Retrieval-Augmented Reasoning?
Retrieval-Augmented Reasoning is an AI architecture where a system:
- retrieves relevant external information,
- incorporates that information into reasoning,
- and generates grounded outputs based on retrieved context.
Instead of relying only on:
internal model memory,
the system dynamically accesses:
- documents,
- databases,
- APIs,
- vector memory,
- or external knowledge systems.
This dramatically improves:
- factual grounding,
- context awareness,
- and reasoning reliability.
Why Retrieval Matters
Traditional language models often:
- generate plausible-sounding outputs,
- but lack reliable grounding.
Even highly capable models may:
- hallucinate facts,
- invent citations,
- or answer confidently while being wrong.
Retrieval systems reduce these problems by allowing AI systems to:
- access real information,
- retrieve relevant context,
- and reason over external knowledge dynamically.
This moves AI systems from:
memorization-based inference
toward:
grounded reasoning architectures.
A Simple Retrieval Example
Imagine asking an AI system:
“Summarize the latest developments in reasoning AI.”
Without retrieval:
- the model may rely on outdated training data.
With retrieval:
- the system searches external sources,
- retrieves relevant documents,
- analyzes the information,
- and generates a grounded summary.
The result becomes:
- more accurate,
- more current,
- and more reliable.
Retrieval-Augmented Generation (RAG)
One of the most common retrieval architectures is:
Retrieval-Augmented Generation (RAG).
RAG systems combine:
- retrieval mechanisms,
- memory systems,
- and language models.
The workflow usually looks like this:
- User submits a query
- Retrieval system searches external knowledge
- Relevant context is retrieved
- The model reasons over the retrieved information
- A grounded response is generated
RAG has become one of the foundational architectures behind:
- enterprise AI,
- document assistants,
- and autonomous knowledge systems.
Retrieval vs Memorization
The distinction between these approaches is increasingly important.
Memorization-Based AI
Traditional models rely heavily on:
- internal training data,
- compressed representations,
- and parameterized knowledge.
Advantages:
- fast inference,
- no external dependencies.
Limitations:
- outdated information,
- hallucinations,
- limited context flexibility.
Retrieval-Augmented AI
Retrieval systems instead:
- dynamically access external knowledge,
- retrieve context during inference,
- and reason over real information.
Advantages:
- current information,
- improved grounding,
- dynamic context.
Limitations:
- retrieval complexity,
- orchestration overhead,
- dependency on retrieval quality.
Core Components of Retrieval-Augmented Reasoning
Modern retrieval systems often combine multiple layers.
Embeddings
Documents and knowledge are converted into:
- vector embeddings,
- semantic representations,
- or latent encodings.
This allows systems to:
- search semantically,
- rather than using keyword matching alone.
Vector Databases
Embeddings are stored inside:
- vector databases,
- semantic indexes,
- or retrieval systems.
These databases enable:
- fast semantic search,
- similarity matching,
- and contextual retrieval.
Retrieval Engines
Retrieval engines identify:
- relevant documents,
- contextual information,
- or related memory.
The system selects information most relevant to:
- the current reasoning task.
Reasoning Layer
The reasoning model then:
- analyzes retrieved information,
- integrates external context,
- and generates grounded outputs.
This creates:
- retrieval-augmented reasoning.
Retrieval and AI Agents
Retrieval is one of the defining capabilities of modern AI agents.
Agents often need to:
- access documentation,
- retrieve workflow state,
- search enterprise knowledge,
- and maintain contextual continuity.
Without retrieval systems, agents remain:
- context-limited,
- and memory-constrained.
Retrieval enables:
- dynamic reasoning,
- adaptive workflows,
- and persistent contextual awareness.
Related article:
- What Are AI Agents?
Retrieval and Memory Architectures
Retrieval systems are deeply connected to:
- memory architectures,
- vector memory,
- and persistent contextual systems.
Agents may retrieve:
- prior conversations,
- workflow history,
- planning state,
- or external documents dynamically.
Retrieval effectively functions as:
externalized memory.
Related article:
- Memory Architectures for AI Agents
Retrieval and Planning Systems
Planning systems often rely heavily on retrieval.
Agents may retrieve:
- objectives,
- prior execution history,
- external documentation,
- or operational constraints.
This improves:
- planning quality,
- workflow coordination,
- and adaptive execution.
Related article:
- Planning Systems in Autonomous AI
Retrieval and Reflection Systems
Reflection systems may retrieve:
- previous reasoning traces,
- failed solutions,
- or verification feedback.
This allows agents to:
- learn from prior execution,
- critique reasoning,
- and improve future decisions.
Related article:
- Reflection Loops in AI Systems
Retrieval and Coding Systems
Coding systems rely heavily on retrieval architectures.
Coding agents may retrieve:
- API documentation,
- repository files,
- test results,
- prior implementations,
- or debugging history.
Retrieval dramatically improves:
- software reasoning,
- debugging quality,
- and code reliability.
Modern coding assistants increasingly function as:
- retrieval-augmented reasoning systems.
Retrieval and Enterprise AI
Enterprise AI systems increasingly depend on retrieval.
Organizations often need AI systems to access:
- internal documents,
- knowledge bases,
- tickets,
- reports,
- policies,
- and operational data.
Retrieval systems allow enterprise AI to:
- ground outputs in organizational knowledge,
- rather than relying purely on training data.
This is becoming one of the largest commercial applications of reasoning AI.
Retrieval and Hallucination Reduction
One of the major benefits of retrieval is:
reduced hallucination risk.
Grounding reasoning in external information helps systems:
- verify facts,
- cite evidence,
- and maintain contextual consistency.
However, retrieval alone does not eliminate hallucinations entirely.
Poor retrieval quality may still produce:
- incorrect,
- irrelevant,
- or misleading context.
This is why modern systems increasingly combine retrieval with:
- verifier models,
- reflection systems,
- and evaluation pipelines.
Related article:
- What Are Verifier Models?
Challenges of Retrieval-Augmented Systems
Although powerful, retrieval architectures introduce major challenges.
Potential issues include:
- retrieval latency,
- irrelevant documents,
- stale information,
- embedding drift,
- retrieval failures,
- or orchestration complexity.
Additional challenges include:
- scalability,
- storage cost,
- synchronization,
- and context management.
This creates important engineering tradeoffs between:
- retrieval quality,
- speed,
- and operational complexity.
Retrieval and Test-Time Compute
Retrieval increases inference-time complexity.
Instead of:
direct generation,
the system:
- searches memory,
- retrieves context,
- evaluates relevance,
- and reasons over external information.
This increases:
- inference cost,
- orchestration complexity,
- and workflow depth.
However, it often dramatically improves:
- factual grounding,
- reasoning quality,
- and reliability.
Related article:
- Test-Time Compute Explained
Emerging Trends in Retrieval-Augmented AI
The field is evolving rapidly.
Modern systems increasingly explore:
- adaptive retrieval,
- memory-aware reasoning,
- retrieval-enhanced planning,
- long-term contextual memory,
- and multi-agent retrieval architectures.
Future AI systems may increasingly function as:
- retrieval-native reasoning architectures.
Practical Applications
Retrieval-Augmented Reasoning is increasingly important for:
- enterprise AI,
- coding systems,
- research assistants,
- autonomous agents,
- scientific AI,
- workflow orchestration,
- and intelligent operations systems.
Applications requiring:
- factual grounding,
- contextual continuity,
- or domain-specific reasoning
often depend heavily on retrieval systems.
Python Example: Simplified Retrieval Workflow
Below is a simplified conceptual example.
query = "latest reasoning AI architectures"documents = vector_db.search(query)response = generate_answer(documents)print(response)
Real retrieval systems often involve:
- embeddings,
- vector databases,
- orchestration pipelines,
- and memory architectures.
Retrieval-Augmented Reasoning and the Future of AI
Retrieval-Augmented Reasoning represents one of the biggest transitions in modern AI architecture.
The industry is increasingly moving from:
static memorization systems
toward:
dynamic reasoning systems capable of retrieving, grounding, and integrating external knowledge during inference.
This transition is influencing:
- reasoning architectures,
- autonomous agents,
- enterprise AI,
- coding systems,
- and cognitive AI research.
Retrieval systems are increasingly viewed as:
one of the foundational mechanisms behind grounded and reliable AI systems.
Related Concepts
- Memory Architectures
- AI Agents
- Tool Calling
- Planning Systems
- Reflection Systems
- Vector Databases
- Retrieval-Augmented Generation
- Workflow Orchestration
- Verifier Models
- Cognitive Architectures
Continue Exploring
To continue exploring reasoning architectures, consider reading:
- Memory Architectures for AI Agents
- Tool Calling Explained
- Reflection Loops in AI Systems
- Planning Systems in Autonomous AI
- What Are Verifier Models?
These concepts build directly on the foundations introduced by retrieval-augmented reasoning systems.
👉 You can experiment with a practical Python implementation of this concept in the official GitHub repository for the Reasoning Systems examples:
