As artificial intelligence systems become increasingly powerful, one major concern is growing rapidly across the AI industry:
Can we still trust benchmark results?
Modern AI models are trained on:
- enormous internet-scale datasets,
- code repositories,
- books,
- research papers,
- websites,
- and public benchmark content.
This creates a serious evaluation problem known as:
benchmark contamination.
Benchmark contamination occurs when:
- benchmark data,
- test questions,
- or evaluation content
appear directly or indirectly inside a model’s training data.
When this happens, benchmark scores may no longer reflect:
- genuine reasoning ability,
- generalization,
- or true intelligence.
Instead, models may partially:
- memorize,
- recognize,
- or reproduce previously seen benchmark patterns.
This issue is becoming increasingly important for:
- reasoning models,
- AI evaluation,
- benchmark design,
- and AGI research.
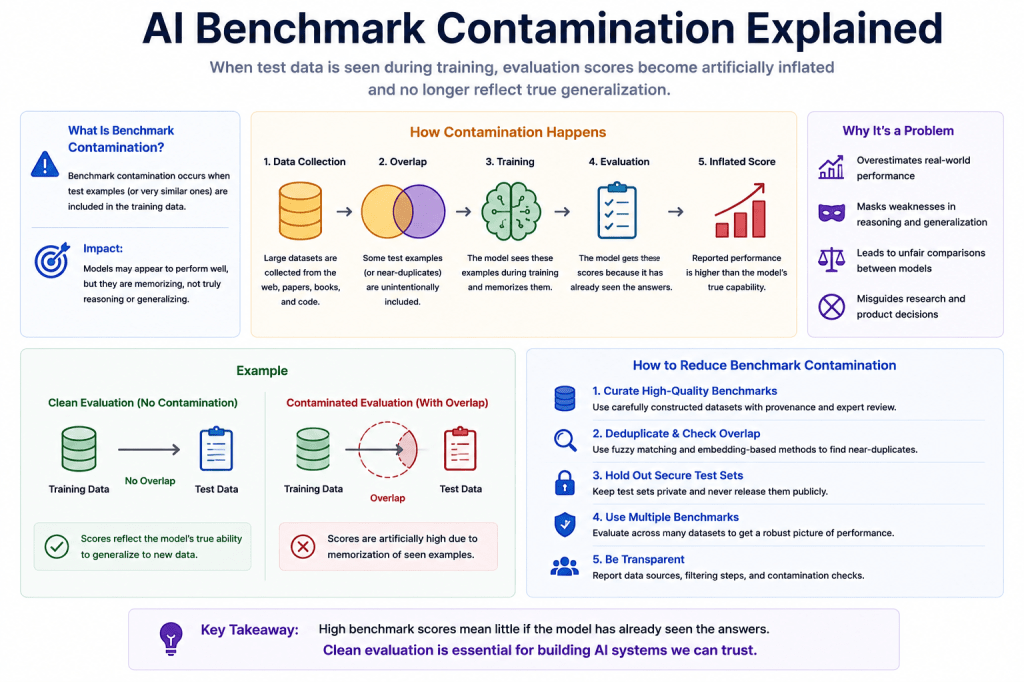
What Is Benchmark Contamination?
Benchmark contamination occurs when an AI model has already been exposed to:
- benchmark questions,
- benchmark answers,
- or highly similar benchmark patterns
during training.
As a result:
- benchmark performance may become artificially inflated.
The system may appear to:
- reason,
- generalize,
- or solve problems,
when in reality it may partially rely on:
- memorization,
- retrieval,
- or statistical familiarity.
This makes evaluation:
- less reliable,
- less interpretable,
- and less trustworthy.
Why Benchmark Contamination Matters
Benchmarks are supposed to measure:
- reasoning,
- intelligence,
- generalization,
- and capability.
If models already “know” benchmark content from training data:
- benchmark scores become misleading.
This creates major problems for:
- research comparisons,
- capability measurement,
- and progress tracking.
Contaminated benchmarks may incorrectly suggest:
- major reasoning improvements,
- when actual generalization capability has changed far less.
A Simple Example
Imagine a benchmark question:
“John has 5 apples and gives away 2. How many remain?”
If the exact question—or extremely similar examples—appeared repeatedly during training:
- the model may simply recognize the pattern.
This is very different from:
reasoning through a genuinely novel problem.
The benchmark then becomes less useful for evaluating:
- true reasoning ability.
Memorization vs Generalization
This distinction is central to modern AI evaluation.
Memorization
Memorization involves:
- reproducing patterns seen during training.
The system may:
- recognize benchmark structure,
- recall similar examples,
- or statistically imitate prior solutions.
Generalization
Generalization involves:
- solving unfamiliar problems,
- adapting to novelty,
- and reasoning beyond training patterns.
Benchmarks ideally aim to measure:
generalization rather than memorization.
Benchmark contamination weakens this distinction.
Why Contamination Is Increasing
Modern AI systems are trained on:
- massive internet-scale corpora.
This often includes:
- public benchmark datasets,
- benchmark discussions,
- GitHub repositories,
- educational websites,
- and benchmark solutions.
As models scale larger:
- avoiding contamination becomes increasingly difficult.
Many older benchmarks are now:
- heavily exposed online,
- and widely discussed publicly.
This dramatically increases contamination risk.
Benchmark Contamination and Large Language Models
Large language models are especially vulnerable to contamination because:
- training data often contains enormous portions of the public internet.
Models may unintentionally ingest:
- benchmark questions,
- answer explanations,
- reasoning traces,
- or solution walkthroughs.
This can inflate:
- benchmark scores,
- while masking actual reasoning limitations.
Benchmark Contamination and Reasoning Benchmarks
Reasoning benchmarks are especially sensitive to contamination.
Benchmarks such as:
- GSM8K,
- ARC-AGI,
- GPQA,
- and SWE-bench
attempt to measure:
- reasoning,
- abstraction,
- and generalization.
If contamination occurs:
- apparent reasoning performance may become misleading.
This is why newer reasoning benchmarks increasingly emphasize:
- novelty,
- expert-generated questions,
- and hidden evaluation datasets.
Related articles:
Benchmark Contamination and Chain-of-Thought
Chain-of-Thought reasoning introduced:
- visible reasoning traces,
- and intermediate reasoning examples.
However, public reasoning traces themselves may become:
- training data contamination sources.
If models repeatedly see:
- benchmark solutions,
- step-by-step walkthroughs,
- or reasoning patterns,
they may:
- imitate reasoning traces,
- rather than generating truly novel reasoning.
Related article:
Benchmark Contamination and Retrieval Systems
Retrieval systems introduce additional complexity.
Modern AI systems may:
- access external knowledge dynamically,
- retrieve benchmark solutions,
- or search online resources during inference.
This makes evaluation increasingly difficult because:
- systems may use external retrieval rather than internal reasoning.
Benchmark design must increasingly consider:
- retrieval-aware evaluation.
Related article:
Benchmark Contamination and Autonomous Agents
Autonomous agents often:
- browse the web,
- retrieve documents,
- and interact with external systems.
This creates new contamination challenges because:
- agents may dynamically access benchmark-related information during evaluation.
Agent evaluation increasingly requires:
- controlled environments,
- isolated testing,
- and monitored execution.
Related article:
Benchmark Contamination and Test-Time Compute
Modern reasoning systems increasingly rely on:
- deliberation,
- search,
- reflection,
- and extended inference-time reasoning.
This complicates contamination analysis because:
- systems may combine:
- memorization,
- retrieval,
- and reasoning dynamically.
Benchmark evaluation is therefore becoming:
- much more complex than simple accuracy measurement.
Related article:
How Researchers Reduce Contamination
Researchers increasingly use several strategies.
Hidden Test Sets
Some benchmarks keep:
- evaluation data private.
This reduces:
- public exposure,
- and training contamination risk.
Expert-Created Questions
Benchmarks such as GPQA use:
- expert-written problems,
- specifically designed to avoid memorized internet patterns.
Dynamic Benchmarks
Some systems generate:
- evolving benchmarks,
- or continuously refreshed tasks.
This reduces:
- benchmark saturation.
Novelty-Focused Evaluation
Researchers increasingly focus on:
- unfamiliar tasks,
- adaptive reasoning,
- and out-of-distribution generalization.
Benchmark Contamination and AI Safety
Benchmark contamination is also important for:
- AI safety,
- governance,
- and capability assessment.
If evaluation becomes unreliable:
- society may misjudge:
- AI capability,
- risk,
- or progress.
This creates major implications for:
- policy,
- oversight,
- and responsible AI development.
Why Benchmark Contamination Is Difficult to Solve
Completely eliminating contamination is extremely difficult because:
- internet-scale training data is enormous,
- benchmark content spreads rapidly online,
- and reasoning traces are increasingly public.
Additionally:
- modern AI systems often blur the boundary between:
- memorization,
- retrieval,
- and reasoning.
Future evaluation systems may therefore require:
- dynamic benchmarks,
- interactive testing,
- and adaptive evaluation frameworks.
Emerging Trends in AI Evaluation
The field is evolving rapidly.
Modern evaluation research increasingly explores:
- hidden benchmark datasets,
- agent-based evaluation,
- interactive reasoning tests,
- adaptive benchmarks,
- and real-world workflow evaluation.
Future AI evaluation may increasingly focus on:
continuous reasoning capability,
rather than:
static benchmark scores.
Practical Importance of Benchmark Contamination
Benchmark contamination is increasingly important for:
- AI evaluation,
- reasoning research,
- AGI assessment,
- benchmark design,
- and frontier model analysis.
Researchers must increasingly ask:
Is the model truly reasoning,
or:
has it partially memorized the benchmark?
This question is becoming central to modern AI research.
Python Example: Simplified Contamination Check
Below is a simplified conceptual example.
benchmark_questions = load_benchmark()training_data = load_training_corpus()matches = search_overlap(benchmark_questions, training_data)print(matches)
Real contamination analysis often involves:
- semantic similarity search,
- embedding analysis,
- and large-scale dataset inspection.
Benchmark Contamination and the Future of AI
Benchmark contamination represents one of the biggest challenges in modern AI evaluation.
The industry is increasingly moving from:
static benchmark scoring
toward:
dynamic reasoning evaluation focused on novelty, generalization, and adaptive intelligence.
This transition is influencing:
- reasoning architectures,
- AI safety research,
- benchmark design,
- autonomous agents,
- and AGI evaluation.
Benchmark contamination is increasingly viewed as:
one of the defining challenges behind trustworthy AI evaluation.
Related Concepts
- ARC-AGI
- GSM8K
- GPQA
- SWE-bench
- Chain-of-Thought Reasoning
- Retrieval-Augmented Reasoning
- Test-Time Compute
- Autonomous Agents
- Reasoning Traces
- Process Supervision
Continue Exploring
To continue exploring reasoning benchmarks and architectures, consider reading:
- What Is ARC-AGI?
- What Is GPQA?
- What Is GSM8K?
- Retrieval-Augmented Reasoning Explained
- Test-Time Compute Explained
These concepts build directly on the evaluation challenges introduced by benchmark contamination.
👉 You can experiment with a practical Python implementation of this concept in the official GitHub repository for the Reasoning Systems examples:
