s artificial intelligence systems become increasingly capable, one question is becoming critically important:
How do we measure real reasoning ability in AI systems?
Traditional AI benchmarks often focus on:
- memorization,
- pattern recognition,
- or narrow task performance.
However, many researchers argue that true intelligence requires something much deeper:
- abstraction,
- adaptation,
- generalization,
- and reasoning across unfamiliar problems.
One of the most influential benchmarks designed to evaluate these abilities is:
ARC-AGI.
ARC-AGI has become one of the most discussed reasoning benchmarks in modern AI research.
It is increasingly important for:
- reasoning models,
- autonomous agents,
- cognitive AI research,
- and general intelligence evaluation.
Unlike many traditional benchmarks, ARC-AGI attempts to measure:
adaptive reasoning rather than memorized knowledge.
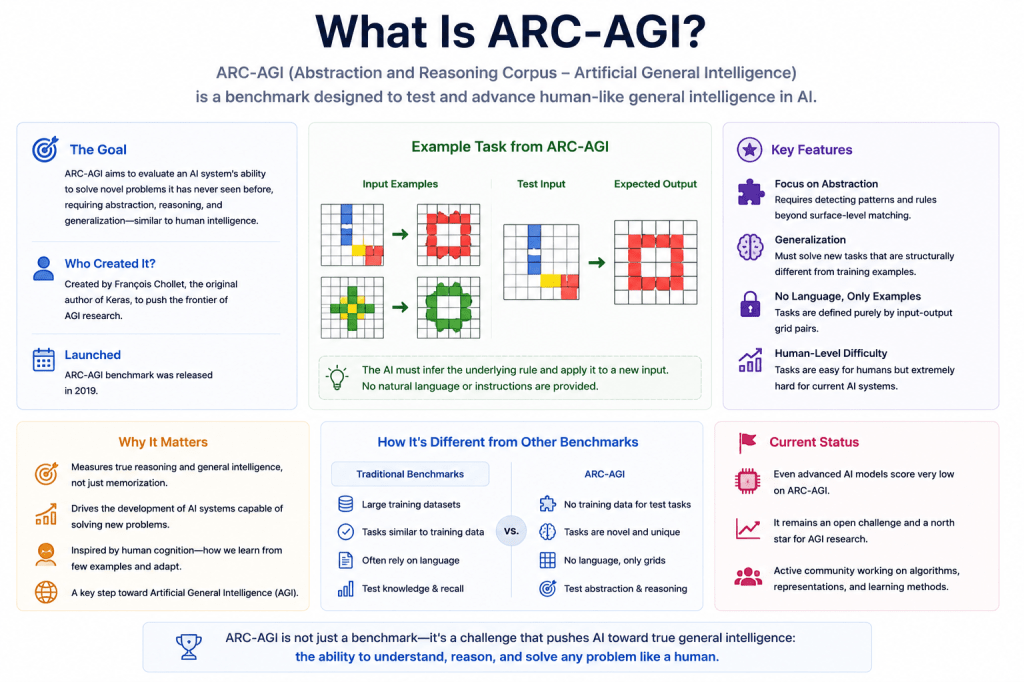
What Does ARC-AGI Mean?
ARC stands for:
Abstraction and Reasoning Corpus.
AGI refers to:
Artificial General Intelligence.
ARC-AGI is a benchmark designed to evaluate whether AI systems can:
- generalize,
- reason abstractly,
- adapt to unfamiliar tasks,
- and solve problems beyond memorized training patterns.
The benchmark was introduced by François Chollet as part of broader research into:
- intelligence measurement,
- generalization,
- and reasoning systems.
Why ARC-AGI Matters
Many AI systems perform extremely well on:
- narrow benchmarks,
- memorized datasets,
- or pattern-heavy evaluations.
However, these systems may still struggle with:
- novel problems,
- abstract reasoning,
- adaptive learning,
- and generalization.
ARC-AGI attempts to evaluate:
whether AI systems can reason in unfamiliar situations with minimal prior exposure.
This makes it one of the most important benchmarks for:
- reasoning AI,
- cognitive architectures,
- and AGI research.
The Core Idea Behind ARC-AGI
ARC tasks are designed around:
- abstract pattern recognition,
- reasoning,
- transformation,
- and generalization.
The system is shown:
- example input-output pairs,
- and must infer the underlying transformation rule.
The AI must then:
- apply the inferred reasoning rule
- to a new unseen example.
The benchmark intentionally avoids:
- large-scale memorization,
- internet-scale factual knowledge,
- or narrow domain specialization.
Instead, it emphasizes:
reasoning and abstraction.
A Simple Conceptual Example
An ARC-style task may involve:
- colored grids,
- visual transformations,
- or abstract symbolic manipulation.
The AI system may observe:
- a pattern transformation,
- such as symmetry,
- object movement,
- duplication,
- or shape completion.
The challenge is not:
memorizing answers,
but rather:
discovering the hidden reasoning rule.
Why ARC-AGI Is Difficult
ARC-AGI is difficult because it tests:
- generalization,
- abstraction,
- and adaptive reasoning.
Many large language models perform well when:
- similar examples existed during training.
ARC instead emphasizes:
- novel tasks,
- unfamiliar reasoning structures,
- and low-data adaptation.
This makes the benchmark much closer to:
- cognitive reasoning,
- than traditional memorization-heavy evaluation.
ARC-AGI vs Traditional Benchmarks
The distinction is important.
Traditional Benchmarks
Many benchmarks focus on:
- factual recall,
- language modeling,
- or narrow task accuracy.
Examples:
- next-token prediction,
- standardized QA datasets,
- benchmark memorization.
These tests often reward:
- scale,
- training data size,
- and statistical pattern learning.
ARC-AGI
ARC-AGI instead focuses on:
- abstraction,
- reasoning,
- adaptation,
- and problem-solving under novelty.
This shifts evaluation toward:
reasoning capability rather than memorization capability.
ARC-AGI and Reasoning Systems
ARC-AGI strongly rewards:
- structured reasoning,
- planning,
- and deliberative inference.
Simple reactive systems often fail because:
- the tasks require:
- decomposition,
- abstraction,
- and reasoning exploration.
Modern reasoning architectures increasingly use:
- Chain-of-Thought reasoning,
- reflection systems,
- verifier models,
- and search-based reasoning
to improve ARC performance.
Related articles:
ARC-AGI and Test-Time Compute
ARC tasks often benefit significantly from:
increased test-time reasoning.
Systems may:
- deliberate longer,
- explore multiple hypotheses,
- revise reasoning,
- and evaluate alternatives.
This makes ARC closely connected to:
- test-time compute scaling,
- and deliberative reasoning architectures.
Related article:
ARC-AGI and Tree-of-Thoughts
Tree-of-Thoughts architectures are especially relevant for ARC-style tasks.
Instead of:
following one reasoning chain,
the system may:
- explore multiple hypotheses,
- compare transformations,
- and search through solution spaces.
This improves:
- abstraction quality,
- reasoning robustness,
- and adaptive problem solving.
Related article:
ARC-AGI and Reflection Systems
Reflection systems may:
- critique reasoning,
- revise hypotheses,
- and improve task-solving iteratively.
ARC problems often require:
- experimentation,
- self-correction,
- and reasoning revision.
Reflection architectures therefore become highly relevant.
Related article:
ARC-AGI and AI Agents
Autonomous agents increasingly require:
- adaptive reasoning,
- problem decomposition,
- and flexible planning.
ARC-style reasoning capabilities are closely related to:
- general autonomous intelligence.
Agents that cannot generalize:
- often fail in unfamiliar environments.
ARC therefore provides useful insights into:
- agent robustness,
- reasoning flexibility,
- and adaptive intelligence.
Related article:
ARC-AGI and Generalization
One of the central goals of ARC is evaluating:
generalization ability.
True intelligence requires systems to:
- adapt to new tasks,
- infer hidden structure,
- and solve unfamiliar problems efficiently.
ARC attempts to measure:
- whether systems can reason beyond training distribution patterns.
This is one of the core challenges of modern AI research.
Why ARC-AGI Is Important for AGI Research
ARC-AGI is often viewed as:
- a proxy for general reasoning ability.
The benchmark attempts to evaluate:
- flexibility,
- abstraction,
- and adaptive cognition.
This makes it highly relevant to discussions involving:
- AGI,
- cognitive architectures,
- and advanced reasoning systems.
Although no benchmark perfectly measures intelligence, ARC is increasingly considered:
one of the strongest evaluations of reasoning-oriented AI capability.
Limitations of ARC-AGI
Although influential, ARC-AGI also has limitations.
Potential criticisms include:
- limited task scope,
- visual bias,
- evaluation subjectivity,
- or benchmark overfitting.
Additionally:
- solving ARC perfectly may not equal human-level intelligence.
However, the benchmark remains highly valuable because it focuses on:
- reasoning,
- abstraction,
- and adaptive problem solving.
Emerging Trends Around ARC-AGI
Modern reasoning systems increasingly explore:
- search-based reasoning,
- reflection-enhanced inference,
- adaptive planning,
- multi-agent collaboration,
- and verifier-guided reasoning
to improve ARC performance.
Future systems may increasingly rely on:
- dynamic reasoning architectures,
- rather than static prediction models.
Practical Importance of ARC-AGI
ARC-AGI is increasingly important for:
- reasoning model evaluation,
- AGI research,
- autonomous agents,
- cognitive AI systems,
- and advanced inference architectures.
Researchers often use ARC to evaluate:
- whether systems truly reason,
- or merely memorize patterns.
This makes ARC one of the most influential reasoning benchmarks in modern AI research.
Python Example: Simplified ARC-Style Reasoning Workflow
Below is a simplified conceptual example.
examples = load_arc_examples()pattern = infer_transformation(examples)solution = apply_transformation(pattern, test_input)print(solution)
Real ARC-solving systems often involve:
- search algorithms,
- reasoning traces,
- reflection loops,
- and planning architectures.
ARC-AGI and the Future of AI
ARC-AGI represents one of the most important shifts in AI evaluation.
The industry is increasingly moving from:
memorization-oriented benchmarks
toward:
benchmarks focused on reasoning, abstraction, and adaptive intelligence.
This transition is influencing:
- reasoning architectures,
- autonomous agents,
- cognitive AI research,
- and AGI development.
ARC-AGI is increasingly viewed as:
one of the foundational benchmarks behind reasoning-oriented AI systems.
Related Concepts
- Chain-of-Thought Reasoning
- Reflection Systems
- Tree-of-Thoughts
- Deliberative Inference
- Test-Time Compute
- Reasoning Traces
- Autonomous Agents
- Cognitive Architectures
- Generalization
- Verifier Models
Continue Exploring
To continue exploring reasoning architectures, consider reading:
- Deliberative Inference Explained
- Reflection Loops in AI Systems
- Tree-of-Thoughts Explained
- Test-Time Compute Explained
- What Are Verifier Models?
These concepts build directly on the foundations introduced by reasoning-oriented benchmarks like ARC-AGI.
👉 You can experiment with a practical Python implementation of this concept in the official GitHub repository for the Reasoning Systems examples:
